最近在处理一些仪器数据,一次采集的数据量比较大,仪器工作150个小时,有3个多g的数据,之前用的处理软件在处理这种超大数据时出现了一些问题,本文主要总结一些处理超大文件的方法。
1. 读入文件数据量大小产生异常,之前是用fseek 和ftell, 程序如下:
复制复制复制复制
复制
int file_size(char* filename)
{
FILE *fp = fopen(filename, "r");
if (!fp) return -1;
fseek(fp, 0L, SEEK_END);
int size = ftell(fp);
fclose(fp);
return size / 2;
}当处理大于2G的数据时,返回-1,产生异常。原因是fseek返回的是long,如果long占四个字节的话,获取的文件大小就不能超过2G了。改成下面的程序即可。
复制复制复制
复制
long long file_size(char* filename)
{
FILE *fp = fopen(filename, "r");
if (!fp) return -1;
fseek(fp, 0L, SEEK_END);
fpos_t pos;
fgetpos(fp, &pos);
fseek(fp, 0, SEEK_SET);
long long size = pos;
fclose(fp);
return size / 2;
}2. 分配存储空间异常
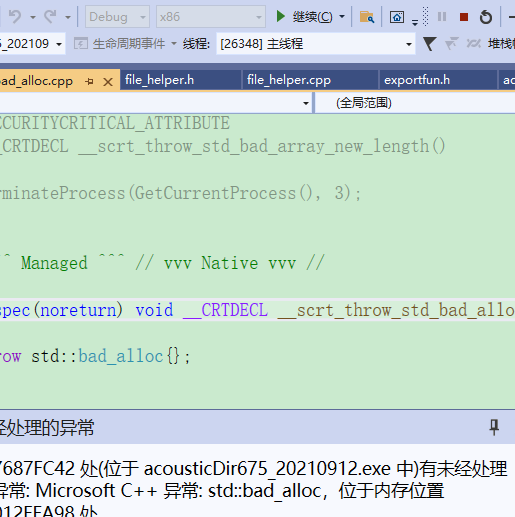
获取数据文件大小以后,准备预分配一个数据存储空间,产生错误:有未经处理的异常: Microsoft C++ 异常: std::bad_alloc。发现原因是在x86环境下调试,内存最大只能使用2G,我的数据超过2G了所以产生异常。将调试环境改成x64后解决问题。
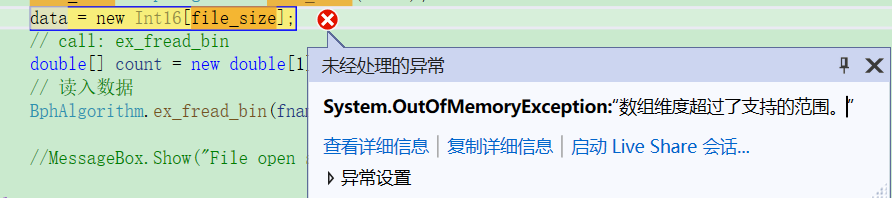
3. 在c#里尝试直接分配一个3g的内存空间,失败。但是又无法将整个项目改成x86环境,原因应该是该项目里有些类库或者动态链接库没有64位的版本。为了解决这个问题。将数据流分批量读入,处理,每批可以处理300M~500M的数据,不影响软件功能并且软件毫无卡顿。当然可以使用这种对数据分页的方法,是基于我的数据流是由独立的数据包流组成,分开读取处理,并不影响。具体的代码见下面:
复制复制
复制
FileStream fileStram = new FileStream(fileName, FileMode.Open, FileAccess.Read);
UInt64 whereToStartReading = (ulong)segDataCb.SelectedIndex* megabyte;
using (fileStram)
{
// 读出选定段的数据流
byte[] buffer = new byte[megabyte];
fileStram.Seek((long)whereToStartReading, SeekOrigin.Begin);
int bytesRead = fileStram.Read(buffer, 0, megabyte); // read in byte sequence
// 将选定段的数据流转换成short array
short[] data = new short[(int)Math.Ceiling(bytesRead / 2.0)];
Buffer.BlockCopy(buffer, 0, data, 0, bytesRead); // byte to short
file_size = bytesRead / 2;
}